pip3 install DBUtils
DBUtils是Python的一个用于实现数据库连接池的模块。
此连接池有两种连接模式:
# BDUtils数据库链接池:
模式一:基于threaing.local实现为每一个线程创建一个连接,关闭是伪关闭,当前线程可以重复
模式二:连接池原理
如果有三个线程来数据库中获取连接:
如果三个同时来的,一人给一个连接;
如果一个一个来,有时间间隔,用一个连接就可以为三个线程提供服务;
其他情况:
有可能:1个连接就可以为三个线程提供服务
有可能:2个连接就可以为三个线程提供服务
有可能:3个连接就可以为三个线程提供服务
PS:maxshared在使用pymysql中均无用。链接数据库的模块:只有threadsafety>1的时候才有用。
模式一:为每个线程创建一个连接,线程即使调用了close方法,也不会关闭,只是把连接重新放到连接池,供自己线程再次使用。当线程终止时,连接自动关闭。(如果线程比较多还是会创建很多连接,推荐使用模式二)
import pymysql
from DBUtils.PersistentDB import PersistentDB
POOL = PersistentDB(
creator=pymysql, # 使用链接数据库的模块
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
closeable=False,
# 如果为False时,conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接)
threadlocal=None, # 本线程独享值得对象,用于保存链接对象,如果链接对象被重置
host="127.0.0.1",
port=3306,
user="root",
password="",
database="code_record",
charset="utf8"
)
def func():
conn = POOL.connection(shareable=False)
cursor = conn.cursor()
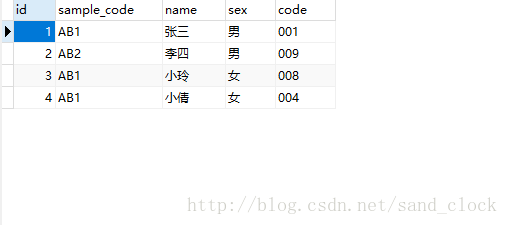
cursor.execute("select * from userinfo")
ret = cursor.fetchall()
print(ret)
cursor.close()
conn.close()
func()
模式二:创建一批连接到连接池,供所有线程共享使用,使用完毕后再放回到连接池。(由于pymysql、MySQLdb等threadsafety值为1,所以该模式连接池中的线程会被所有线程共享。)
import pymysql
from DBUtils.PooledDB import PooledDB
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3,
# 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用,如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host="127.0.0.1",
port=3306,
user="root",
password="",
database="code_record",
)
def func():
# 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常
# 否则
# 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。
# 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。
# 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,再封装到PooledDedicatedDBConnection中并返回。
# 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。
conn = POOL.connection()
cursor = conn.cursor()
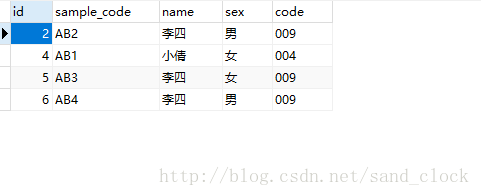
cursor.execute('select * from userinfo')
result = cursor.fetchall()
print(result)
conn.close()
func()
为什么要使用数据库连接池呢?
如果没有连接池,使用pymysql来连接数据库时,单线程应用完全没有问题;但如果涉及到多线程应用那么就需要加锁,一旦加锁那么连接势必就会排队等待(无法并发),当请求比较多时,性能就会降低了。
加锁
import pymysql
import threading
from threading import RLock
LOCK = RLock()
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='',
database='code_record',
charset='utf8')
def task(arg):
with LOCK:
cursor = CONN.cursor()
cursor.execute('select * from userinfo')
ret = cursor.fetchall()
cursor.close()
print(ret)
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
不加锁(报错)
import pymysql
import threading
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='',
database='code_record',
charset='utf8')
def task(arg):
cursor = CONN.cursor()
cursor.execute('select * from userinfo')
ret = cursor.fetchall()
cursor.close()
print(ret)
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()